
I’m a bit of a research methods geek. As I’ve become more familiar with qualitative methods and coding data, there’s a few tricks I’ve learned which I’ll discuss today. Disclaimer: I’m not a methods “expert” (though I’m not sure many people are), and I developed this approach from experience and exhaustive reading 👨🏼💻 of the academic literature.
I enjoy working with both numbers (quantitative data) and documents (qualitative data). Qualitative methods are interesting because they provide the researcher an enormous amount of flexibility, and the data often provides a great depth of understanding. The downside to qualitative approaches are that they’re a bit fuzzy. There’s also A LOT of qualitative techniques. You have to be comfortable with loose approaches to analyzing data and, occasionally, creating your own method – usually derived from one or more existing approaches – to fit your project. However, while the methods can be flexible, it’s important to employ your method as consistently as possible.
First, some background. I’m currently conducting a content/policy analysis of Open Education Resources Policy in Western Canada. You don’t have to know what that is. What’s important is that my data is 100% web documents. There are no experiments to run, no statistics to gather, and no people to interview. (Well… I chose not to interview this time around).
Within the documents I collected, I’m looking for snippets of text that make mention of my topic and I’m assigning those snippets a “code.” If you’re not familiar with coding I’ve included a couple of solid resources:
- Qualitative Codes and Coding (SlideShare) – Heather Ford
- Why do We Code? (YouTube) – ModU
So, here’s what I’m looking at…

This is one of my Excel sheets. I prefer to organize data I’ve found using Excel because programs such as NVivo don’t seem as flexible. Each row is a separate document and the columns label the information in each cell.
Tip 1: Colour Code and Prioritize
It looks like a mess, I know, but there’s a logic. Green rows means I’ve read and coded the document. White rows mean that I’ve skipped those documents for now. These docs might be useful, but certain types of documents are hit or miss with regards to relevance. Conversely, others are DEFINITELY what I want. Time is precious, so working in order of relevance, not chronological, is key.
At this point you might be thinking “What a waste of time! Why collect irrelevant documents?” But, wait!
Tip 2: Collect everything you find as you go, and deal with it later
Time is precious, and it’s likely I’m going to do a “similar” project on the same topic (because it’s interesting). Re-finding documents I’ve already come across is a waste of time, so it’s best to collect them as you find them. Always be thinking of how documents could be useful to you one, two, three, or ten-years down the road. All documents that could be useful later are indicated by the dark blue cells on the left. This process also helps limit the scope of what you analyze. A minute saved is a minute earned? (I just made that up).
Tip 3: Multiple Excel sheets!
It’s imperative to have multiple sheets when coding with Excel. Snippets of text are on the left, and a code is assigned to each snippet.
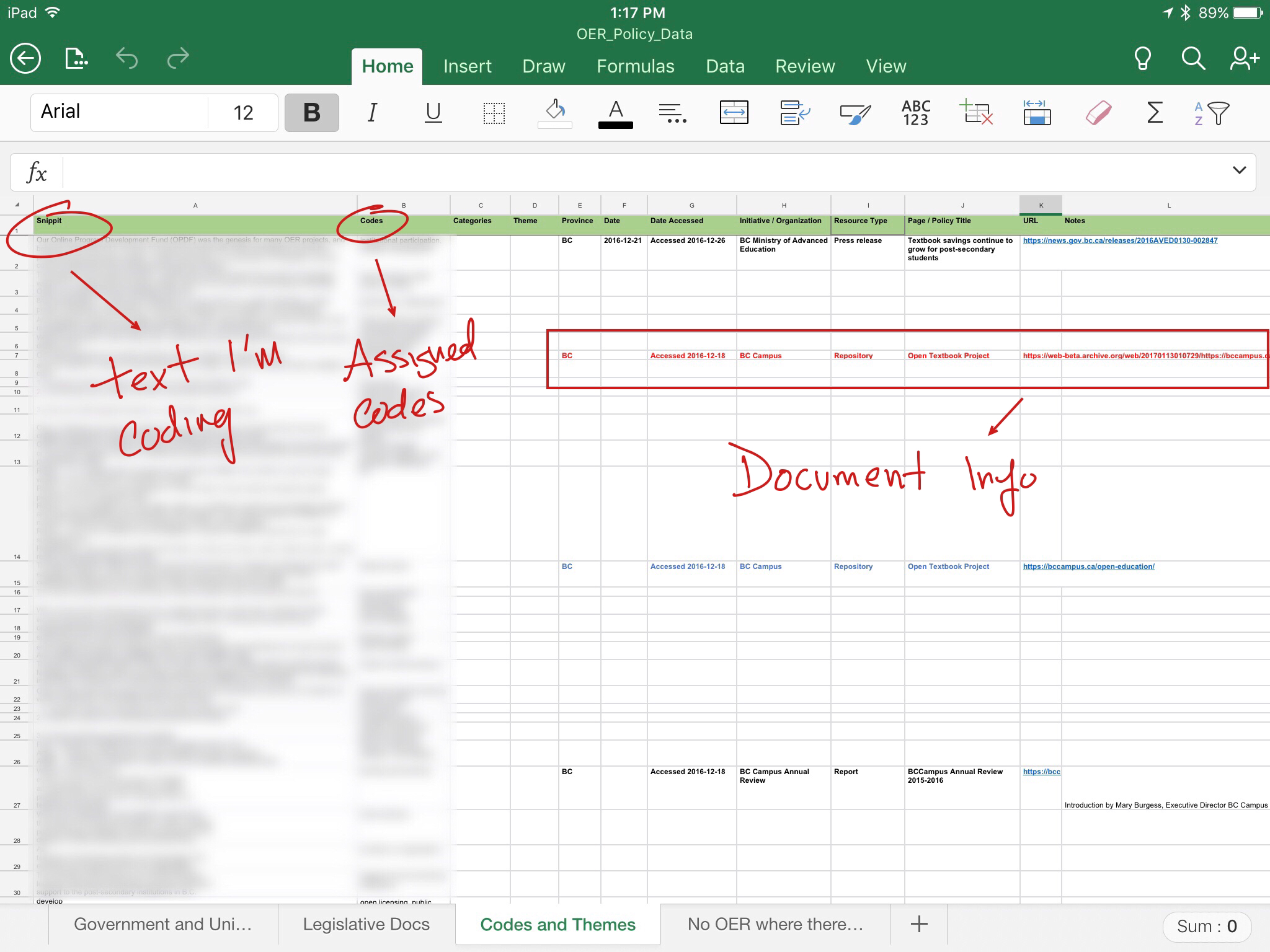
I also have the document details on the right, in the same format as the previous sheet. Some people don’t agree with this approach because you’re not separating yourself from the documents when creating themes from your codes. My work around is to cover up these details when I organize my codes into themes. Just temporarily shade cells you don’t want to see in black. Problem solved!

Leave a comment